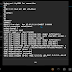
install modem SmartFren AC682 di Android
Android-x86 meMakai Modem Smartfren AC682... Dialer Khusus Usb Modem Evdo Rev.A (Testing di Smartfren AC682) Caranya : DOW...
Android-x86 meMakai Modem Smartfren AC682... Dialer Khusus Usb Modem Evdo Rev.A (Testing di Smartfren AC682) Caranya : DOW...
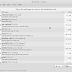
Membuat Repository Lokal BlankOn Linux Tidak banyak, tepatnya : sangat sedikit, untuk saat ini, pengguna komputer di Indon...
wget -q "http://deb.playonlinux.com/public.gpg" -O- | sudo apt-key add - sudo wget http://deb.playonlinux.com/playonlinux_oneiric....
Sora o kakeru hikouki Mado kara miorosu kumo wa yuki no you Anata no sumu basho e to mukatte Kono kokoro wa yurete imasu Kisetsu mo jika...
August 31, 2006 In the old days (say, around 1990) a must-have application when buying a computer was an encyclopedia on a...
Most of what my work online either involves checking mail or browsing forums for getting answers or reading Wikipedia for getting informati...