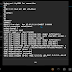
install modem SmartFren AC682 di Android
Android-x86 meMakai Modem Smartfren AC682... Dialer Khusus Usb Modem Evdo Rev.A (Testing di Smartfren AC682) Caranya : DOW...
Android-x86 meMakai Modem Smartfren AC682... Dialer Khusus Usb Modem Evdo Rev.A (Testing di Smartfren AC682) Caranya : DOW...
Membuat Repository Lokal BlankOn Linux Tidak banyak, tepatnya : sangat sedikit, untuk saat ini, pengguna komputer di Indon...
wget -q "http://deb.playonlinux.com/public.gpg" -O- | sudo apt-key add - sudo wget http://deb.playonlinux.com/playonlinux_oneiric....
Sora o kakeru hikouki Mado kara miorosu kumo wa yuki no you Anata no sumu basho e to mukatte Kono kokoro wa yurete imasu Kisetsu mo jika...
August 31, 2006 In the old days (say, around 1990) a must-have application when buying a computer was an encyclopedia on a...
Most of what my work online either involves checking mail or browsing forums for getting answers or reading Wikipedia for getting informati...
Karena banyak sohib-sohib yang sering menanyakan hal seperti ini “ Gimana cara agar bisa berbagi paket ke orang lain dari paket yang sudah t...
Version 7.0 of Komodo IDE and Komodo Edit are now available for download. This brief tutorial is going to show you how to install Komodo...
Praktek membuat repository offline Ubuntu, berbekal file-file .deb yang kita download kemarin, plus sebuah paket bernama dpkg-dev... S...
Sumber : http://joherujo.blogspot.com/2009/09/setup-tv-tuner-di-ubuntu.html "Watching TV broadcasting on multimedia computer has...
Install LightRead in Ubuntu 12.04 Want to try it right now? You can – just add ppa:cooperjona/lightread to your Software Sources , update...
Ini untuk catatan pribadi saya, jadi maaf kalau membuat anda bingung :) sudo add-apt-repository ppa:upubuntu-com/xampp sudo apt-get...
Ini untuk catatan pribadi saya, jadi maaf kalau membuat anda bingung :) wget http :// wordpress . org / latest . tar . gz tar xfvz wordpre...
Banyak orang yang berpendapat bahwa pemrograman tidak perlu dipelajari teorinya, cu kup dipraktikkan saja. Kita tinggal baca buku contohcon ...
OpenOffice.org telah merajai aplikasi perkan toran open source selama sepuluh tahun. Program yang lain seperti KOffice dan GNOME Office masi...

Untuk yang ingin mempunyai atau ingin mendapat backlink gratis saya punya sedikit tips jitu untuk anda yang ingin mempunyai banyak backlin...
Memang ada beberapa cara untuk meningkatkan pengunjung website beberapa diantarnya adalah dengan mensubmit artikel ke Social Bookmark , tuk...
sudo apt-get install subtitleripper arahkan terminal ke folder tempat vob berada masukkan peintah panjang berikut ini ke dalam terminal past...